What is Apache Hadoop definition and need of Hadoop
What is hadoop definition and need?
Definition of Hadoop:
Today our data growing so rapidly on internet and these data
are unstructured format. The time has come for you to re-check your approach to
data storage, data management, and data paralytics.
Hadoop framework for programming:
Hadoop is a free open source, Java-based framework for
programming that supports the processing of large data sets in a distributed
computing environment. It is part of the Apache project sponsored by the Apache
Software Foundation.
Hadoop can handle all types of data from disparate systems:
structured, unstructured, log files, pictures, audio files, text – just about
anything you can think have, regardless of its native format. Furthermore, you
can put it all in your Hadoop cluster with no prior need for a schema. In other
words, you don’t need to know how you intend to query your data before you
store it
What Is Apache Hadoop?
The Apache Hadoop project develops open-source software for
reliable, scalable, distributed computing.
- Framework that allows for the distributed processing.
- It is designed to scale up from single servers to thousands of machines.
- Highly-available service on top of a cluster of computers for storing large amount of data.
The Hadoop project includes
these modules:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System: A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
HDFS (Hadoop Distributed File System):
- Support for POSIX-style filesystem extended attributes. See the user documentation for more details.
- Using the OfflineImageViewer, clients can now browse an fsimage via the WebHDFS API.
- The NFS gateway received a number of supportability improvements and bug fixes. The Hadoop portmapper is no longer required to run the gateway, and the gateway is now able to reject connections from unprivileged ports.
- The SecondaryNameNode, JournalNode, and DataNode web UIs have been modernized with HTML5 and Javascript.
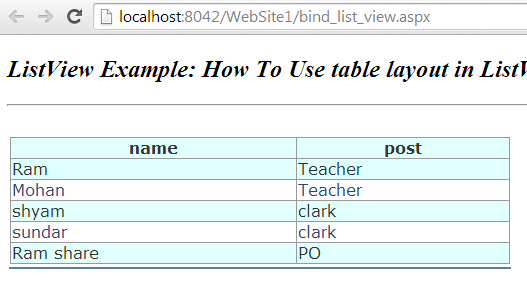
very nice..
ReplyDelete